Fact laundering: AI research tools find facts and lose the source
We asked nine AI research products to research the same thirty news stories. On one of them, Lululemon cutting its full-year outlook, one of the strongest briefs came back with every number right: the new revenue guidance, the lowered EPS range, the margin compression, a paragraph of analyst reaction. It had even found Lululemon’s own press release. The release sat in its source list, two lines below the blog it actually cited for the guidance figures.
That brief gets the facts right and still fails an editor. A reader who checks the central claim lands on a content farm instead of the company. If the blog garbled a number, you now own that error under your name. And because the citation points elsewhere, you cannot tell whether the tool read the original or a rewrite of it.
We call this failure fact laundering: the fact survives, the source a reader could check does not. We built a benchmark to measure it, and every product we tested does it. The best launders in 5 percent of its briefs, the worst in nearly half.
A benchmark for sourcing, not summarising
JournoBench measures a research agent the way an editor checks a story before it runs: did the facts come from the right place, and can anyone trace them back?
Each of the thirty cases is a real news event with a seed of around twenty words, the length of a real tip. Every event postdates the training cutoff of every model tested, so a correct answer is evidence of research, never recall. We wrote each answer key from the primary source itself, committed and froze the case set before any agent ran, and scored every brief on the same checks: did it reach the primary source, carry the key facts, carry the supporting detail, cite the facts to that source, and avoid contradicting a known fact.
We tested three kinds of product a newsroom could buy: Velora’s research agent, the model-plus-search offerings from Google, OpenAI, and Anthropic, and the purpose-built answer engines Perplexity and Linkup. Full disclosure up front: we build Velora. The harness, every case, every answer key, and all 540 scored briefs are public, and you can run the whole thing yourself.
What we found
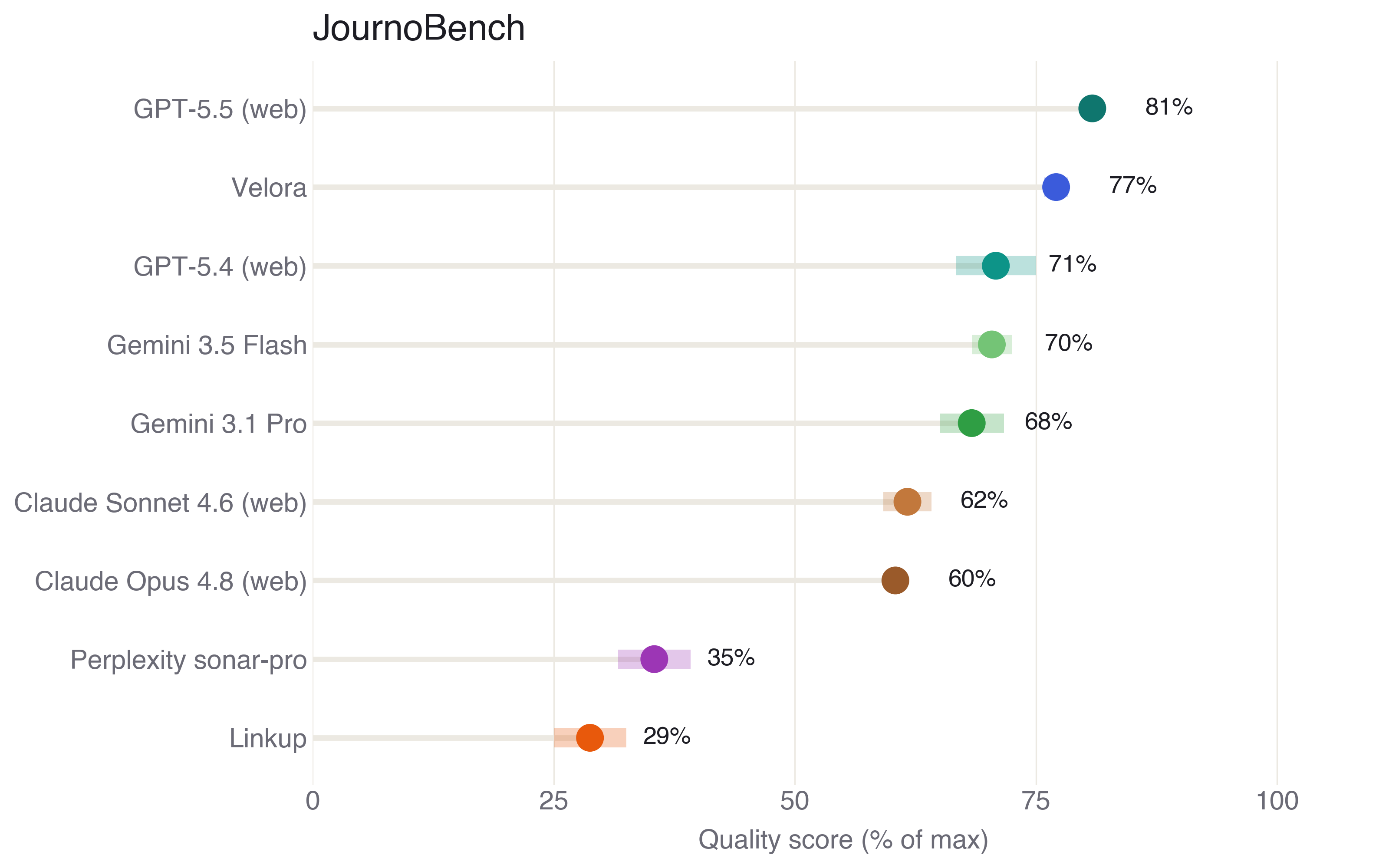
GPT-5.5 leads at 81 percent. Velora follows at 77, then GPT-5.4 and the two Gemini models in a band around 70. Claude Sonnet 4.6 and Opus 4.8 sit at 62 and 60, and a wide gap opens to Perplexity sonar-pro at 35 and Linkup at 29.
The more interesting result is where the points are lost. Almost every tool finds the key facts. They separate on the two things a newsroom cannot compromise: reaching the primary source, and tying each fact back to it.
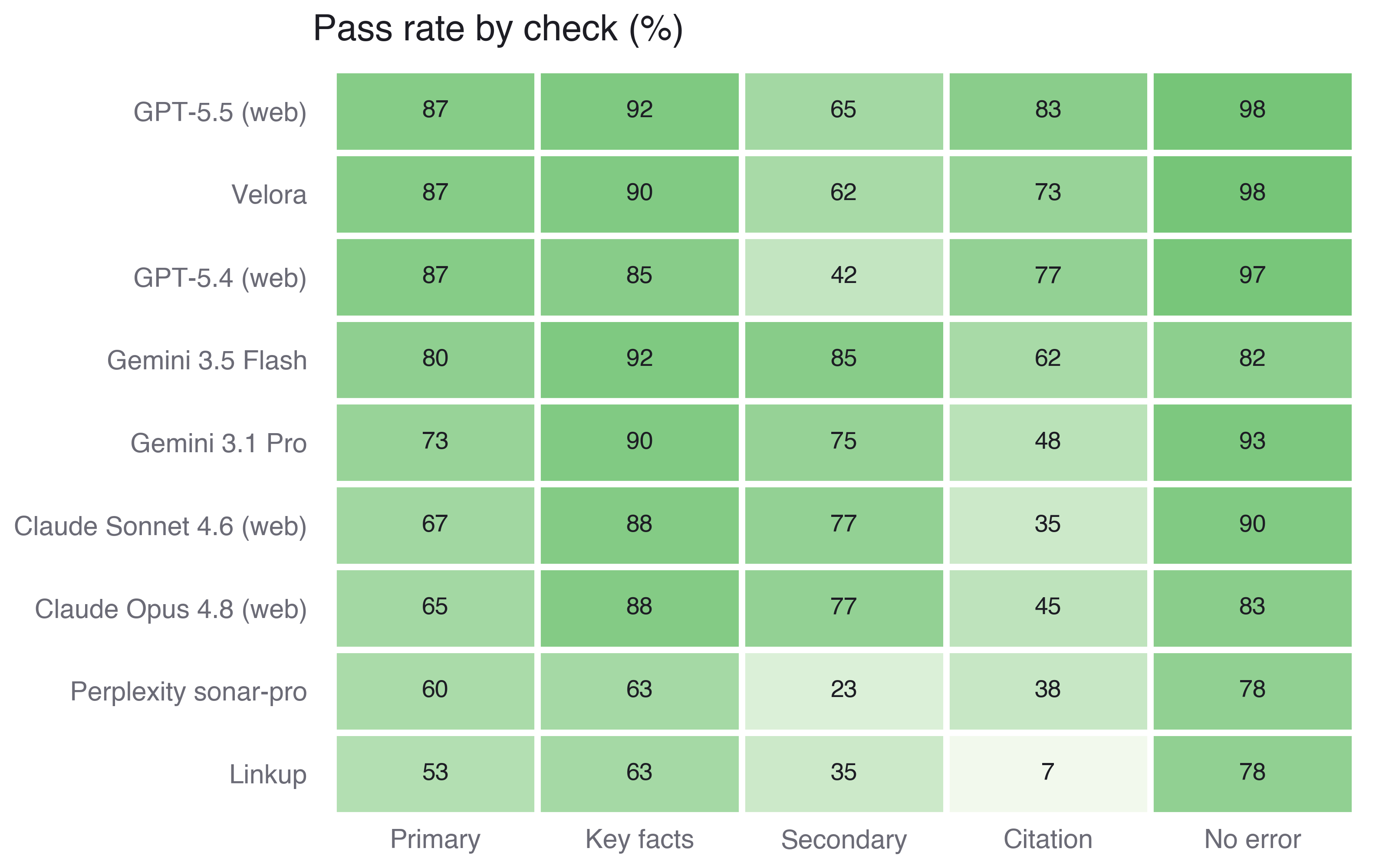
The tools that gather the most detail cite it the least. Claude Sonnet 4.6 writes the fullest briefs in the field and earns the citation point in 35 percent of cases. Linkup reaches the primary in half its briefs and cites it in 7 percent. The facts are right, and they are unsourceable.
Price predicts quality only at the bottom
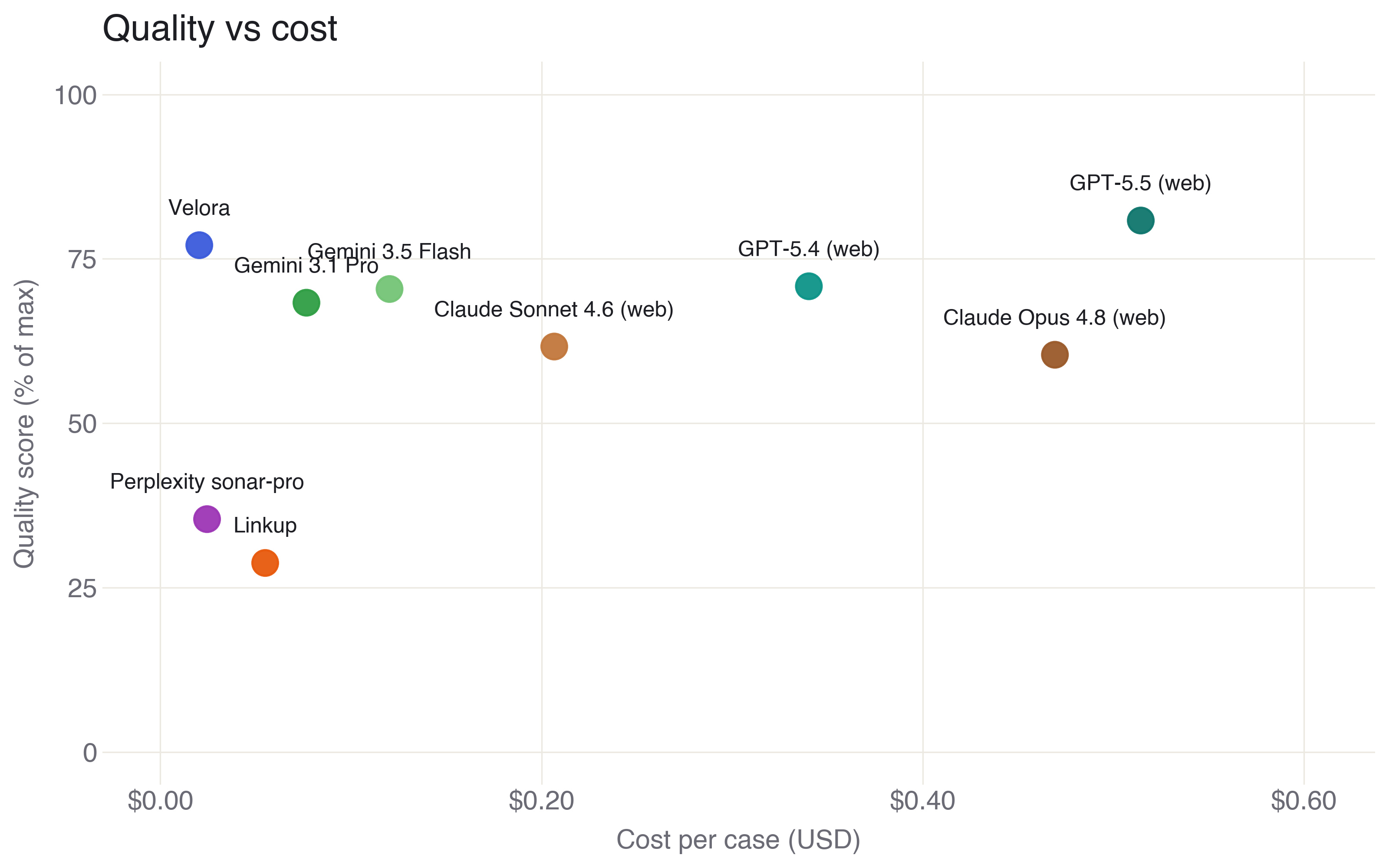
The cheapest tools score lowest, but above the floor the relationship breaks. GPT-5.5 pays the field’s highest price for its lead, around fifty cents a case. Claude Opus 4.8 costs more than twenty times Velora and scores 17 points lower. Velora’s run costs around two cents a case.
Cost turns out to be a property of behaviour, not list price. A run’s bill depends on how many searches the tool fires and how much retrieved context it reads, which is how Gemini 3.5 Flash undercuts 3.1 Pro on token rates yet costs half as much again per case.
Where Velora loses points
A benchmark from a vendor should report its own failures, so here is ours. Velora ties for the field’s best rate of reaching the primary source and keeps the joint-cleanest briefs, but it carries the full supporting record in only 62 percent of cases, behind the Gemini and Claude models. It reaches and cites the source better than it elaborates on it. That is the axis we are working on next.
Read the full report
The full write-up covers the answer-key design, the judge, the failure modes, and the per-case results: download the report (PDF).
Everything behind it is open. The harness, the cases, the frozen answer keys, the judge prompt, and every scored brief live at github.com/velora-digital/journo-bench. Adding a case is one YAML file; adding a provider is one adapter. If you think your research tool sources better, run it.
Velora helps publishers draft faster. We monitor your sources, research each story, and deliver structured drafts to your CMS — so editors can focus on what matters.

Written by
Danny Bellion
Co-founder of Velora and former Head of AI at Capital on Tap. Builds the AI-powered content tools behind Velora, informed by nearly two decades of engineering and product experience.
LinkedIn →